Bedrijven in Nederland leveren jaarlijks miljoenen rapportages (zoals jaarrekeningen, vastgoedtaxaties en belastingaangiften) aan overheden en banken. Deze rapportages bevatten waardevolle data. Maar waar organisaties tegenaan lopen is dat deze in XBRL opgestelde rapportages niet leesbaar zijn voor data analytische software. Om deze XBRL gegevens bruikbaar te maken voor analyse, deden we een experiment met de KVK.
Experiment
KVK ontvangt jaarlijks jaarrekeningen van ondernemend Nederland waarvan een groot gedeelte in XBRL. Met de analyse van grote hoeveelheden jaarrekeningen - op een correcte manier - wil de KVK waardevolle inzichten genereren voor haar klanten. Denk aan een analyse die laat zien hoe jij het als ondernemer doet vergeleken met anderen in dezelfde sector of meer algemeen ‘wat speelt er in ondernemend Nederland’. Deze data-analyses bieden ondernemers inzichten die kunnen helpen bij het maken van keuzes en het realiseren van doelstellingen.
Om bedrijven, industrieën en boekjaren met elkaar te kunnen vergelijken is het nodig dat de gegevens uit de XBRL berichten worden gehaald om bruikbaar te zijn voor business intelligence software. KVK heeft samen met SBR Vernieuwing een experiment gedaan om XBRL data op een bruikbare manier op te slaan in een database. Deze proof of concept (PoC) aanpak is een methode om te demonstreren of bijvoorbeeld een idee, technologie of functionaliteit haalbaar is.
Aanpak/resultaat
De eerste uitdaging was om de data uit de individuele XBRL bestanden te halen. Hiervoor is een tool ontwikkeld die uit 15 duizend jaarrekeningen 2 miljoen numerieke waarden heeft gehaald en vertaald naar CSV formaat. CSV is een gangbaar formaat voor het importeren van grote hoeveelheden gegevens. Door de gegevens vervolgens op te slaan in een database kan men deze combineren met andere gegevensstromen. Ook zijn de gegevens/data dan eenvoudig (gedeeltelijk) beschikbaar te stellen (via een API) voor in- en externe gebruikers en applicaties.
Bij het ontwerp van de database hebben we gekeken naar opdrachten (query’s) die een gebruiker zou willen geven aan een database. Voor een gedeelte zijn er generieke XBRL tabellen aangemaakt en voor een ander gedeelte zijn er tabellen op maat gemaakt voor de wens van KVK. Op deze manier hebben we grootte van elke tabel te beperkt zodat het opvragen van resultaten sneller verloopt.
Verwerkingsproces
- Losse XBRL-rapportages
- Eén bestand met alle gerapporteerde waarden en hun context
- Een SQL-database met bestanden
- Dashboard is direct verbonden met database
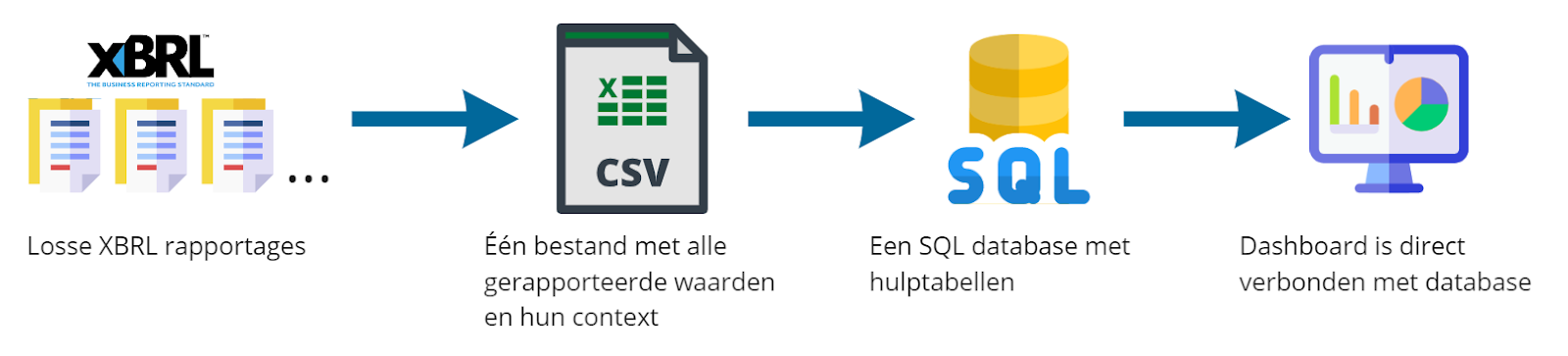
Als laatste stap in het experiment hebben we de bruikbaarheid van de database getest. KVK had de wens om alle jaarrekeningen (visueel) te kunnen vergelijken. Daarvoor hebben we gebruik gemaakt van PowerBI dashboards. Deze dashboards geven een grafische representatie van de data en zijn up-to-date door een directe connectie met een database. Je ziet in één oogopslag hoe de zaken ervoor staan.
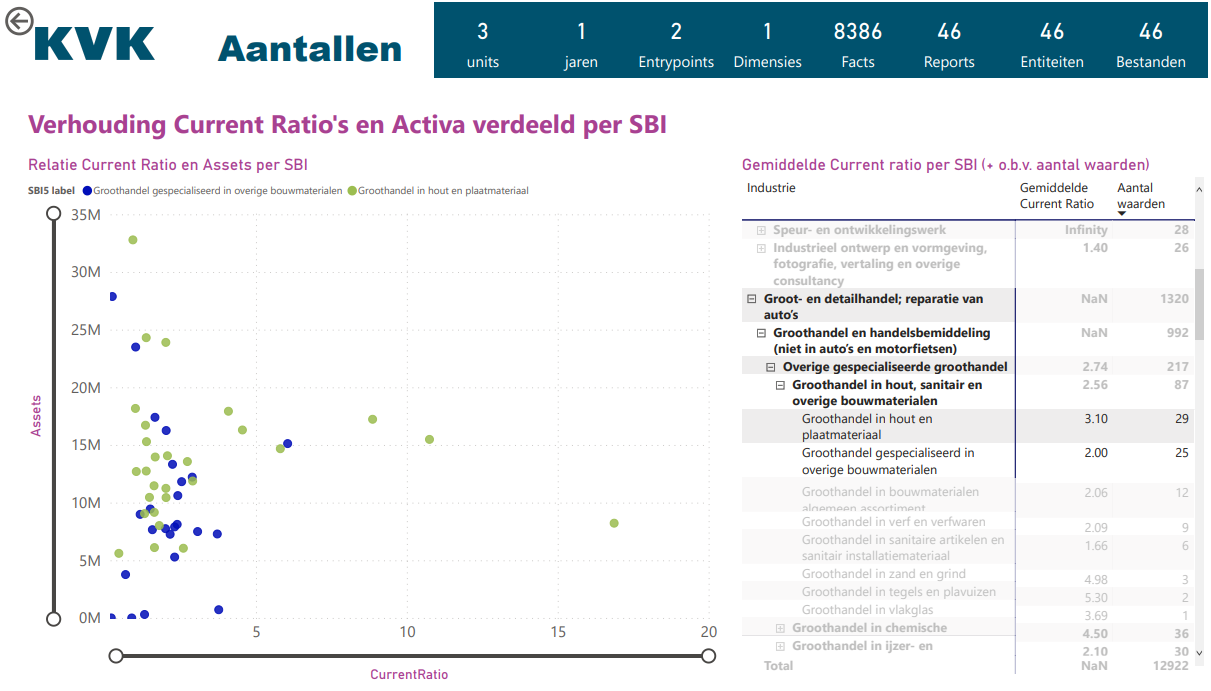
In de dashboards kunnen kengetallen worden berekend per boekjaar, bedrijfsklasse en/of bedrijfstak. Zoals in onderstaande afbeelding, waarin de current ratio’s (laten de liquiditeit van een bedrijf zien) van twee bedrijfstakken met elkaar worden vergeleken en grafisch worden gepresenteerd.
Lessons learned
Door een proof of concept database te maken hebben we de volgende lessen geleerd:
- Zorg dat je weet wat je met de data wilt alvorens je je database inricht. Dit bepaalt namelijk hoe je de data beschikbaar wilt stellen.
- Begin met een kleine hoeveelheid data, dat kost minder rekenkracht en versnelt het ontwikkelproces. Daarna kun je meer data toevoegen.
- Bij de inrichting van de database is kennis van XBRL vereist om ervoor te zorgen dat gebruikers deze specialistische kennis niet nodig hebben.
Vragen?
Neem contact op met het Kenniscentrum XBRL via kenniscentrumxbrl@logius.nl